
The distribution of code
When monitoring the health of a codebase, one smell is file size. Excessive file size may indicate, for example, breach of the Single Responsibility principle of SOLID. So it is tempting to track the maximum file size over the hierarchy of the project.
Unfortunately, this strategy necessarily finds the outliers. The reason a file may be bloated is that it contains boilerplate in which case the tracking of this information is of no use to the developer. It is possible that small file size is also of interest. For example, books for learning C in the early 90's showed the wonders that could be achieved in only a single line of clever code of dubious maintainability.
To avoid being distracted by outliers if an appropriate probability distribution is available then confidence intervals can be calculated. To determine the distribution the files from an ARM build of the Linux kernel 4.6 were analysed. This comprises of 19912871 lines in 42186 files, which gives a mean of 472 lines per file. Taking the logarithm of the file size results in a rough normal curve.
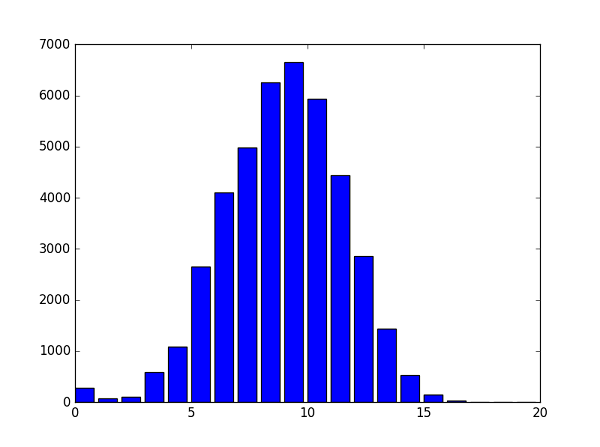
This has been used to implement 90% confidence intervals in the coupling analysis performed by DeepEnds where it is used to identify code smells (see the columns marked Lower and Upper).